 PoBot
PoBot
 Optimisation de code
Optimisation de codeEnfin un petit article simple sur l’optimisation de code. Alors bien sûr, il n’est pas question de parler ici d’assembleur contre langage C ou de Java contre C++, car tout le monde sait bien que le C bien compilé est plus rapide que du code en assembleur et que Java est plus performant que C++.
On va donc rester dans un même langage (ici ce sera le C) et montrer par l’exemple et chronomètre en main comment optimiser le temps de calcul de routines élémentaires.
Notre matériel est simple :
– un microcontrôleur (ici une carte mySmartControl à base d’AVR ATmega8)
– un compilateur C (ici avr-gcc et WinAVR)
– un analyseur logique (ici l’excellent Logic de Saleae) pour mesurer les progrès réalisés
Le premier exemple est très classique : prenons un développeur de robot lambda, plus doué avec Linux qu’avec un système temps réel. Il doit allumer et éteindre tout un tas de leds. Plutôt que d’écrire 20 fois la même ligne, il va... utiliser une boucle et une variable bien sûr !
Voici le code qu’il écrirait :
//----- Include Files ---------------------------------------------------------
#include "avr/io.h" // include I/O definitions (port names, pin names, etc)
#include "avr/interrupt.h" // include interrupt support
#include "global.h" // include our global settings
#include "timer.h" // include timer function library (timing, PWM, etc)
int main(void)
timerInit() ;
DDRC = 0xFF ; // port C en sortie
while (1)
int i=0 ; // la variable sans laquelle l’informaticien est perdu
// lancer un front haut pour démarrer le chrono
sbi(PORTC,0) ;
// allumer toute la série de leds
for (i=1 ;i<5 ;i++)
sbi(PORTC,i) ;
// les éteindre dans le sens contraire
for (i=4 ;i>0 ;i—)
cbi(PORTC,i) ;
// un front bas pour éteindre le chrono
cbi(PORTC,0) ;
delay_ms(1) ;
return 0 ;
Tout est correct, ça compile et ça prend pas beaucoup de place. On charge et on regarde combien ça prend de temps...
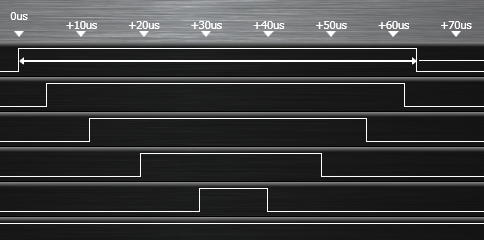
Argh ! 65 µs c’est quand même beaucoup pour allumer 5 leds. En effet, la carte utilisée a un quartz à 3.6864 MHz (millions de tops d’horloge par secondes) et comme on utilise un microcontrôleur performant, il lui faut juste 2 tops d’horloge pour changer un port d’entrée/sortie de niveau, soit
0,54 µs (microsecondes ou millionièmes de secondes).
Pour optimiser, il suffit d’enlever la boucle et d’utiliser directement les instructions "sbi" et "cbi" (pour "Set BIt" et "Clear BIt") qui correspondent à deux instructions de base du jeu réduit de cette famille (RISC ou Reduced Instruction Set Computer).
Le code devient :
//----- Include Files ---------------------------------------------------------
#include "avr/io.h" // include I/O definitions (port names, pin names, etc)
#include "avr/interrupt.h" // include interrupt support
#include "global.h" // include our global settings
#include "timer.h" // include timer function library (timing, PWM, etc)
int main(void)
timerInit() ;
DDRC = 0xFF ; // port C en sortie
while (1)
// lancer un front haut pour démarrer le chrono
sbi(PORTC,0) ;
// allumer toute la série de leds
sbi(PORTC,1) ;
sbi(PORTC,2) ;
sbi(PORTC,3) ;
sbi(PORTC,4) ;
// les éteindre dans le sens contraire
cbi(PORTC,4) ;
cbi(PORTC,3) ;
cbi(PORTC,2) ;
cbi(PORTC,1) ;
// un front bas pour éteindre le chrono
cbi(PORTC,0) ;
delay_ms(1) ;
return 0 ;
Alors oui ça peut prendre plus de place quand on a 100 leds à allumer ou éteindre, mais le résultat est là :
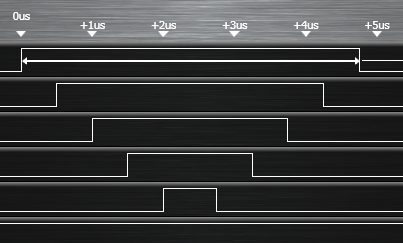
Oui, pas plus de 4.8 µs. D’ailleurs c’est logique, pas de superflu : 8 instructions à 0.54 µs, cela fait 4.32 µs + la demi microseconde pour redescendre le signal de notre témoin pour la mesure (première ligne du chronogramme, patte 0 du port C dans le code).
Ok... hmm... ah oui... j’en étais sûr, vous vous dites que s’il y a 100 leds donc 100 lignes pour allumer les leds, on va utiliser une fonction cachée tout en bas du fichier source, pour garder un code "propre", du genre :
//----- Include Files ---------------------------------------------------------
#include "avr/io.h" // include I/O definitions (port names, pin names, etc)
#include "avr/interrupt.h" // include interrupt support
#include "global.h" // include our global settings
#include "timer.h" // include timer function library (timing, PWM, etc)
void allumer(void) ;
void eteindre(void) ;
int main(void)
timerInit() ;
DDRC = 0xFF ; // port C en sortie
while (1)
// lancer un front haut pour démarrer le chrono
sbi(PORTC,0) ;
// allumer toute la série de leds
allumer() ;
// les éteindre dans le sens contraire
eteindre() ;
// un front bas pour éteindre le chrono
cbi(PORTC,0) ;
delay_ms(1) ;
return 0 ;
void allumer(void)
// pourrait faire 100 lignes de ce genre :
sbi(PORTC,1) ;
sbi(PORTC,2) ;
sbi(PORTC,3) ;
sbi(PORTC,4) ;
sbi(PORTC,4) ;
void eteindre(void)
cbi(PORTC,4) ;
cbi(PORTC,3) ;
cbi(PORTC,2) ;
cbi(PORTC,1) ;
Regardons le résultat :
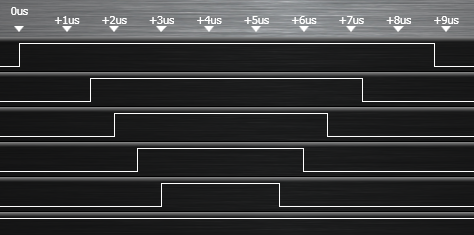
Et oui, 9 µs. On voit bien où le temps est perdu : à l’appel de la fonction et au retour (espaces allongés entre la première et la seconde ligne et écart plus grand au milieu de la dernière ligne, entre les deux appels). En effet, un "contexte" (les registres de mémoire, etc.., voir le détail dans un ouvrage spécialisé sur les µC Atmel) est sauvegardé, il faut empiler et dépiler les valeurs à l’appel et au retour.
Mais rien n’est perdu, une instruction spécifique existe : "inline" qui permet avant compilation de placer tout le code contenu dans la fonction à chaque emplacement qui appelle la fonction inlinée (comme les macros #define).
Voici le code :
//----- Include Files ---------------------------------------------------------
#include "avr/io.h" // include I/O definitions (port names, pin names, etc)
#include "avr/interrupt.h" // include interrupt support
#include "global.h" // include our global settings
#include "timer.h" // include timer function library (timing, PWM, etc)
void inline allumer(void) ;
void inline eteindre(void) ;
int main(void)
timerInit() ;
DDRC = 0xFF ; // port C en sortie
while (1)
// lancer un front haut pour démarrer le chrono
sbi(PORTC,0) ;
// allumer toute la série de leds
allumer() ;
// les éteindre dans le sens contraire
eteindre() ;
// un front bas pour éteindre le chrono
cbi(PORTC,0) ;
delay_ms(1) ;
return 0 ;
void inline allumer(void)
// pourrait faire 100 lignes de ce genre :
sbi(PORTC,1) ;
sbi(PORTC,2) ;
sbi(PORTC,3) ;
sbi(PORTC,4) ;
void inline eteindre(void)
cbi(PORTC,4) ;
cbi(PORTC,3) ;
cbi(PORTC,2) ;
cbi(PORTC,1) ;
Et voici le résultat :
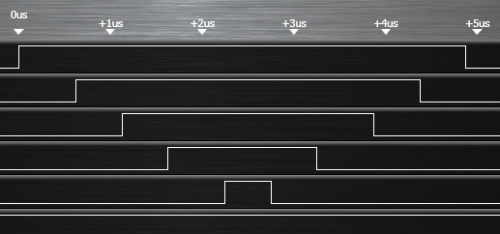
On retrouve bien nos 5 microsecondes !
N’hésitez pas à me contacter pour me faire part de vos propres optimisations et pour compléter cet article.





Vos commentaires
# Le 3 février 2018 à 13:11, par marref mohammed amine En réponse à : Optimisation de code
En réponse à : Optimisation de code
bonjour a tous s’il vous plaît j’ai besoin d’aide pour un programme C....je veux créer un signal carré avec une fréquence variable en fonction de temps est-ce qu’il y a quelqu’un ici pour m’aider merci d’avance [->sba55_5@outlook.fr]
# Le 4 février 2018 à 23:04, par Eric P. En réponse à : Optimisation de code
En réponse à : Optimisation de code
Bonjour,
Un programme C censé tourner sur quel type de matériel ? PC ? Arduino ? Raspberry Pi ?
Si c’est pour Arduino, je vous suggère d’étudier les exemples de programmes fournis avec l’environnement. La réponse à la question que vous posez s’y trouve.
Cordialement.
Répondre à ce message
# Le 6 mars 2009 à 15:19, par jbe En réponse à : Optimisation de code
En réponse à : Optimisation de code
Bravo, une manipulation sympa.
Un soucis, l’instruction inline va donc rajouter n fois le bloc lorsqu’il sera appelé, et donc rajouter n fois des lignes dans le programme compilé.
Mais c’est comme d’habitude, un compromis entre temps d’exécution et taille mémoire.
De plus, pourriez vous faire cette même manipulation en utilisant la bibliothèque sbit.h.
Une utilisation de cette bibliothèque est écrite ci dessous.
Ce qui m’intéresse, c’est l’utilisation de sbit , par rapport a cbi et sbi.
/** Algo Studio - SansNom **/
#define F_CPU 1000000UL
#include <inttypes.h>
#include
#include
#include
#include
#define bp0 SBIT (PIND, 0)
#define bp1 SBIT (PIND, 1)
#define bp2 SBIT (PIND, 2)
#define bp3 SBIT (PIND, 3)
#define LED0 SBIT (PORTB, 0)
#define LED1 SBIT (PORTB, 1)
#define LED2 SBIT (PORTB, 2)
#define LED3 SBIT (PORTB, 3)
/*** le code exécutable commence ici ***/
int main(void) // 5
Debut Prog(RESET)DDRD =0b00000000 ;
DDRB= 0b11111111 ;
do // 2
Début d'itération perpétuelleif (bp0 == 1)
LED0 = 1 ;
else
LED0 = 0 ;
// 3
Fin d'itération perpétuellewhile(1) ;
return 0 ; // exigé par le compilateur WinAVR
// Fin de la fonction "main"
/* Fin du texte */
Cordialement
jbe
# Le 7 mars 2009 à 10:48, par Julien H. En réponse à : Optimisation de code
En réponse à : Optimisation de code
Je ne suis pas d’accord avec la première conclusion : ça rajoute du code dans le programme à compiler et pas forcément das le programme compilé. C’est-à-dire que la vision "naïve" (au sens premier du mot, pas critique) est que le contenu de la fonction "inline" est copié partout où c’est appelé, mais en fait les compilateurs modernes (dont avr-gcc) vont détecter qu’il s’agit du même code donc vont optimiser le code binaire (et même le code assembleur) en faisant de la mutualisation. Donc la taille de programme n’en souffre pas. Je ferai un test pour le vérifier, mais c’est déjà le cas pour un code sans inline. Si vous écrivez 10 fois une séquence d’opérations identiques, le compilateur ne le transcrit qu’une fois en code assembleur et fait des appels (qui ne sont pas aussi coûteux qu’un appel de fonction C puisque pas de pile (stack) à gérer. Si le coût est quand même trop grand (2 appels de pointeurs), on peut régler ce paramètre avec les options de compilation -O1, -O2, -O3, -Os (s = size).
Je ferai le test avec SBIT.
# Le 7 mars 2009 à 17:14, par ? En réponse à : Optimisation de code
En réponse à : Optimisation de code
Julien,
Tu as trop parlé ou pas assez.
1 Qu’est ce que c’est cette optimisation du programme compilé.
Aurais tu quelques exemples ?
2 Sais tu comment s’en sort notre compilateur préféré, AVR GCC.
3 Il faudrait monter une manipulation pour comparer différent compilateur. Il y a par exemple Code Vision, ICC de chez Image Craft, Keil C.
# Le 7 mars 2009 à 17:22, par ? En réponse à : Optimisation de code
En réponse à : Optimisation de code
Utilisation de SBIT
Bien, j’ai fait quelques essais de mon coté.
J’ai compilé le programme ci dessus, avec l’option s.
Le programme assembleur utilise alors les instructions sbit et cbit.
Donc le code est optimisé au maximum.
L’utilisation de sbit.h est à généraliser de toute urgence.
JBE
# Le 8 mars 2009 à 19:17, par Julien H. En réponse à : Optimisation de code
En réponse à : Optimisation de code
1) il y a plusieurs options à la compilation. Dans un makefile standard (livré avec WinAVR ou AVRlib, ce sont les options "#compiler flags".
Exemple :
"-Os" signifie qu’il optimise la taille du programme .hex à transférer dans le chip
"-Wall" signifie qu’il montre tous les warnings.
Je vous laisse consulter la doc pour le reste :)
2) Il s’en sort bien. Attention à certaines optimisations (-O3) qui supprime des boucles vides qui servent d’attente en fonction du test effectué par le while()
3) les autres compilateurs sont payants, seules les écoles peuvent se les payer, pas de pauvres amateurs comme nous. Donc pas de test de comparaison à moins de recevoir une aide financière.
# Le 8 mars 2009 à 19:31, par Julien H. En réponse à : Optimisation de code
En réponse à : Optimisation de code
Attention : "sbit" et "cbit" ne sont pas des instructions. SBI et CBI sont des instructions.
On ne peut pas dire une optimisation "au maximum", il faut dire si on optimise en taille ou en mémoire ou en temps d’exécution.
# Le 11 mars 2009 à 15:02, par jbe En réponse à : Optimisation de code
En réponse à : Optimisation de code
Ces donc le rôle de ces différentes options de compilation :
taille, place mémoire, ou temps d’exécution,
que l’on a dans AVR GCC.
Si tu as le numéro de la page de la doc AVR GCC où ceci est expliqué, je suis preneur.
Cordialement
JBE
# Le 11 mars 2009 à 16:31, par Julien H. En réponse à : Optimisation de code
En réponse à : Optimisation de code
Oups, AVR-GCC a une doc ? En fait je ne l’ai jamais lue, je réutilise ce que je connais "de loin" dans les compilateurs similaires. Mais ce serait intéressant de connaitre le détail, je te l’accorde.
# Le 30 avril 2011 à 02:16, par ? En réponse à : Optimisation de code
En réponse à : Optimisation de code
Pas mal du tout cette page ! J’en ai appris des choses.
Donc, les appels de fonctions sont chères en temps à cause de la pile.
Mais comment sont gérées les variables statiques ?
J’ai des fonctions prenant beaucoup de paramètres (genre 30 bytes pour un petit AVR) et je me rends compte que c’est très lent. Comment améliorer cela ? Variables statiques ? Plusieurs appel de fonction plus petites ? Pas d’appel de fonction ?
Ces fonctions rendent mon code c plus lisible. Si j’utilise "inline", les appels seront supprimés et mon code tournera plus vite ?
Merci pour tes réponses si tu passes par ici 🙂
# Le 3 mai 2011 à 19:48, par Julien H. En réponse à : Optimisation de code
En réponse à : Optimisation de code
Bonjour,
Les variables statiques sont mises dans un emplacement mémoire fixe qui ne change pas. Chaque écriture ou lecture se fait à la même adresse.
30 octets c’est beaucoup trop. Fais une structure (struct) pour couvrir tous tes paramètres, et passe la structure en paramètre. Fais des tests :)
Oui, avec inline ça tournera plus vite.
Répondre à ce message