 PoBot
PoBot
 La localisation des sources de son : portage en C++ / ALSA
La localisation des sources de son : portage en C++ / ALSAUn environnement de développement C++
Première étape pour notre portage, avoir un environnement de développement.
On porte un projet Java développé avec Eclipse donc...va pour Eclipse !
Le module de développement C++ pour Eclipse s’appelle CDT. Vous trouverez ça dans votre distribution préférée.
Dans mon cas une Ubuntu, donc lancement de Synaptic (package manager), recherche du package ’eclipse-cdt’, installation.
Il nous faut aussi un compilateur si il n’est pas déjà installé, donc installation du package g++ au passage.
A la découverte du son Linux : ALSA
Pour faire nos jolis traitements sur le son, il faut d’abord l’échantillonner.
Sous Linux, la couche bas niveau ’universelle’ d’accès au son est l’Advanced Linux Sound Architecture (ALSA).
Les APIs de base sont assez simple, et il existe quelques tutoriaux simples desquels s’inspirer. Bon ça date un peu, mais les APIs n’ont pas trop changé.
Pour pouvoir développer avec ALSA, il nous faut la librairie et les headers de développement. La librairie est libasound2, les headers sont dans le package ’libasound2-dev’ que l’on installe donc avec son package manager préféré.
Voila, on est fin prêt pour créer un projet C++ dans Eclipse, et commencer à sampler du son.
Ouvrons la carte son :
#include
int err ;
snd_pcm_t* _capture_handle ;
const char* device = "plughw:0,0" ;
if ((err = snd_pcm_open(&_capture_handle, device,
SND_PCM_STREAM_CAPTURE, 0)) < 0)
fprintf(stderr, "cannot open audio device %s (%s)\n", device,
snd_strerror(err)) ;
exit(1) ;
Ici on ouvre le premier périphérique de son, le "0,0".
Adaptez à votre configuration si vous avez plusieurs cartes son.
Il y a deux façons d’ouvrir ce périphérique : avec "hw:0,0", ou avec "plughw:0,0".
Dans le premier cas, le périphérique est ouvert dans son mode le plus direct, et le plus rapide.
– Avantage : il n’y a pas de traitement logiciel additionnel sur la machine hôte, ça va vite !
– Inconvénient : on ne peut demander à la carte que ce dont elle est capable directement, notamment en terme de fréquence d’échantillonnage, de précision d’échantillons, etc.
Dans le second cas, le périphérique est ouvert avec une couche d’adaptation ALSA.
– Avantage : on peut demander des choses dont n’est pas directement capable la carte, la couche intermédiaire va l’émuler à partir du hardware existant. On peut par exemple demander des échantillons en float sur deux canaux alors que la carte échantillonne un seul canal en 8 bits.
– Inconvénient : ça prend du CPU
Dans le cas d’une solution embedded, on va préférentiellement prendre "hw:0,0", en faisant attention ensuite à adapter le code aux capacités exactes du hardware que l’on a.
Pour le moment, restons un peu génériques, et partons sur "plughw:0,0" : on fera néanmoins attention à ne pas demander de choses trop "exotiques", pour se préparer aux optimisations futures.
On peut maintenant configurer l’échantillonnage à 44 kHz (qualité CD), 16 bits, deux canaux : des caractéristiques "usuelles".
On demande aussi à obtenir les deux canaux "NON_INTERLEAVED", c’est a dire en deux buffers séparés (’a1 a2 a3 ....’ et ’b1 b2 b3 ...’) plutôt qu’un seul buffer aux échantillons entrelacés (’a1 b1 a2 b2 a3 b3 ....’).
C’est parti :
snd_pcm_hw_params_t* hw_params ;
if ((err = snd_pcm_hw_params_malloc(&hw_params)) < 0)
fprintf(stderr,
"cannot allocate hardware parameter structure (%s)\n",
snd_strerror(err)) ;
exit(1) ;
if ((err = snd_pcm_hw_params_any(_capture_handle, hw_params)) < 0)
fprintf(stderr,
"cannot initialize hardware parameter structure (%s)\n",
snd_strerror(err)) ;
exit(1) ;
if ((err = snd_pcm_hw_params_set_access(_capture_handle, hw_params,
SND_PCM_ACCESS_RW_NONINTERLEAVED)) < 0)
fprintf(stderr, "cannot set access type (%s)\n", snd_strerror(err)) ;
exit(1) ;
if ((err = snd_pcm_hw_params_set_format(_capture_handle, hw_params,
SND_PCM_FORMAT_S16_LE)) < 0)
fprintf(stderr, "cannot set sample format (%s)\n",
snd_strerror(err)) ;
exit(1) ;
int soundSamplingRate=44100 ;
if ((err = snd_pcm_hw_params_set_rate_near(_capture_handle, hw_params,
&soundSamplingRate, 0)) < 0)
fprintf(stderr, "cannot set sample rate (%s)\n", snd_strerror(err)) ;
exit(1) ;
if ((err = snd_pcm_hw_params_set_channels(_capture_handle, hw_params, 2))
< 0)
fprintf(stderr, "cannot set channel count (%s)\n",
snd_strerror(err)) ;
exit(1) ;
if ((err = snd_pcm_hw_params(_capture_handle, hw_params)) < 0)
fprintf(stderr, "cannot set parameters (%s)\n", snd_strerror(err)) ;
exit(1) ;
snd_pcm_hw_params_free(hw_params) ;
if ((err = snd_pcm_prepare(_capture_handle)) < 0)
fprintf(stderr, "cannot prepare audio interface for use (%s)\n",
snd_strerror(err)) ;
exit(1) ;
Voila, c’est tout prêt !
On peut maintenant obtenir les échantillons avec un simple :
const int bufferSize = 4096 ;
short rightBuffer[bufferSize] ;
short leftBuffer[bufferSize] ;
short* bufs[2] ;
bufs[0] = rightBuffer ;
bufs[1] = leftBuffer ;
int err ;
if ((err = snd_pcm_readn(_capture_handle, (void**) bufs, bufferSize))
!= bufferSize)
fprintf(stderr, "read from audio interface failed (%s)\n",
snd_strerror(err)) ;
exit(1) ;
Localisation du son
Maintenant que l’on sait échantillonner du son, il n’y a plus qu’à porter le code Java de l’article précédent en C++.
Pas de révolution, mais les échantillons sont maintenant représentés par des entiers et non des flottants : attention aux types de données et aux possibles dépassements de capacité (overflow) dans les calculs ! On en profite pour optimiser un peu et on adapte la syntaxe de ci de la.
Il faut noter qu’il y a encore beaucoup d’optimisations possibles, notamment au niveau du calcul du niveau du son (on fait plein de multiplications pour avoir un résultat mathématiquement exact...mais pas utile en pratique. Pas très "Pobot attitude" 😉 ). On optimisera tout ça plus tard pour l’embedded.
Bref, un fois porté on obtient :
Notre classe principale, avec ses champs et son initialisation :
#define SAMPLE_TYPE short
/**
* This class computes the direction of the source of the sound it hears.
*
* It uses 2 microphones, and compute the time of arrival difference of sound
* between them to estimate the sound source localization.
*/
class SoundSourceLoc
/**
* Max time shift between right and left mic in number of samples.
* This typically depends on the sample rate and the distance between
* microphones.
* You can either compute this with clever formulas involving sound speed
* and microphones distance, or just try and put the max value you get with
* extreme loc of sound. Guess what I did 🙂
*/
static const int _nbSamplesMaxDiff = 13 ;
/**
* Buffer size on which we will try to locate sound.
* This is a number of samples, and depends on sample rate, and speed of
* sound loc change we want to detect. Lower values mean compute sound loc
* often, but accuracy is quite low as we compute on a very small slice of
* sound.
* Empirically, I found that computing on long sounds is better, here 4096
* samples at 44 KHz sampling rate means about one second of sound => we
* reevaluate sound loc every second.
* Notice that the larger the value, the most computation we do, as we time
* shift on the whole buffer.
*/
static const int _bufferSize = 4096 ;
/**
* Take a point for sound loc is level > 105% of mean level.
* This allows to compute sound loc only for "meaningful" sounds, not
* background noise.
*/
static const float _minLevelFactorForValidLoc = 1.05f ;
/**
* sound speed in meters per seconds
*/
static const float _soundSpeed = 344 ;
/**
* sound sampling rate in Hz
*/
unsigned int _soundSamplingRate ;
/**
* Distance between microphones in meters
*/
static const float _distanceBetweenMicrophones = 0.1f ;
/** An utility to compute the running average of sound power */
RunningAverage* _averageSoundLevel ;
/** ALSA sound input handle */
snd_pcm_t* _capture_handle ;
/** sound samples input buffer */
SAMPLE_TYPE _rightBuffer[_bufferSize] ;
SAMPLE_TYPE _leftBuffer[_bufferSize] ;
public :
SoundSourceLoc()
_averageSoundLevel = new RunningAverage(50) ;
_soundSamplingRate = 44100 ;
// sampling : 2 chanels, 44 KHz, 16 bits.
/** Clean exit */
SoundSourceLoc()
snd_pcm_close(_capture_handle) ;
delete _averageSoundLevel ;
La boucle principale de traitement du son :
/**
* Main loop : read a buffer, compute sound source localization, iterate.
*/
void run()
while (true)
processNextSoundBlock() ;
/**
* This is the core of the sound source localization : it takes the
* right/left sampled sounds, and compute their differences while delaying
* one channel more and more.
* => the delay for which the difference is minimal is the real delay
* between the right/left sounds, from which we can deduce the sound source
* localization
*/
void processNextSoundBlock()
SAMPLE_TYPE* bufs[2] ;
bufs[0] = _rightBuffer ;
bufs[1] = _leftBuffer ;
int err ;
if ((err = snd_pcm_readn(_capture_handle, (void**) bufs, _bufferSize))
!= _bufferSize)
fprintf(stderr, "read from audio interface failed (%s)\n",
snd_strerror(err)) ;
exit(1) ;
// compute the sound level (i.e. "loudness" of the sound) :
SAMPLE_TYPE level = computeLevel(_rightBuffer, _leftBuffer) ;
// update the average sound level with this new measure :
_averageSoundLevel->newValue(level) ;
// relative sound level of this sample compared to average :
float relativeLevel = (float) level
/ (float) _averageSoundLevel->getMean() ;
int minDiff = INT_MAX ;
int minDiffTime = -1 ;
// ’slide’ time to find minimum of right/left sound differences
for (int t = -_nbSamplesMaxDiff ; t < _nbSamplesMaxDiff ; t++)
// compute sum of differences as the cross-correlation-like measure :
int diff = 0 ;
for (int i = _nbSamplesMaxDiff ;
i < _bufferSize - _nbSamplesMaxDiff - 1 ; i++)
diff += abs(_leftBuffer[i] - _rightBuffer[i + t]) ;
if (diff < minDiff)
minDiff = diff ;
minDiffTime = t ;
// if sound is loud enough, and not an extreme (=usually false
// measure), then output it :
if ((relativeLevel > _minLevelFactorForValidLoc)
&& (minDiffTime > -_nbSamplesMaxDiff)
&& (minDiffTime < _nbSamplesMaxDiff))
// computation of angle depending on diff time, sampling rates,
// and geometry (thanks Mathieu from Pobot 🙂 ) :
float angle =
-(float) asin(
(minDiffTime * _soundSpeed)
/ (_soundSamplingRate
* _distanceBetweenMicrophones)) ;
cout << angle << " ;" << relativeLevel << endl ;
La boucle principale reprend le principe :
- sampling (échantillonnage)
- calcul de la puissance (niveau de son)
- calcul du décalage du son entre les deux "oreilles" = direction
- si le son est plus fort que la moyenne, on publie la direction
Notez qu’on calcule la direction même si on ne la publie pas... à optimiser, décidément 🙂 !
La boucle principale s’appuie sur une petite fonction pour calculer le niveau, extrêmement optimisable elle aussi :
/**
* Compute average sound level (i.e. power) for left/right channels.
*
* Notice we could probably do the computation on some samples only (for
* example one over 4 samples) without loosing much accuracy here. This
* would reduce computation time.
* Also, as we are only interested in relative evolution, we could
* simplify and avoid the multiplications by just taking the mean of
* absolute values ?
*/
SAMPLE_TYPE computeLevel(SAMPLE_TYPE right[], SAMPLE_TYPE left[])
float level = 0 ;
for (int i = 0 ; i < _bufferSize ; i++)
float s = (left[i] + right[i]) / 2 ;
level += (s * s) ;
level /= _bufferSize ;
level = sqrt(level) ;
return (SAMPLE_TYPE) level ;
et sur une petite classe utilitaire pour retenir le son moyen :
class RunningAverage
int _nbValuesForAverage ;
int _nbValues ;
float _mean ;
public :
RunningAverage(int nbValuesForAverage)
_nbValuesForAverage = nbValuesForAverage ;
_mean = 0 ;
_nbValues = 0 ;
void newValue(SAMPLE_TYPE v)
if (_nbValues < _nbValuesForAverage)
_nbValues++ ;
_mean = ((_mean * (_nbValues - 1)) + v) / (float)_nbValues ;
SAMPLE_TYPE getMean()
return (SAMPLE_TYPE) _mean ;
;
Voila, on a tout, avec un petit main() pour lancer le tout :
int main(int argc, char *argv[])
SoundSourceLoc soundLoc ;
soundLoc.run() ;
Visualisation du résultat
Bon, les calculs c’est bien, mais une suite d’output texte ce n’est pas très parlant...
Il faudrait une représentation graphique de la direction du son.
Une approche possible est de coder une petite représentation graphique en C++, avec les librairies GTK ou QT par exemple. Hum, sans doute amusant, mais ce n’est pas le but de l’exercice donc...
...place à la solution de fainéant : on réutilise notre interface précédente en Java.
L’avantage est qu’elle peut continuer à tourner sur une machine déportée, même si on déplace l’exécution de la localisation du son sur une carte embarquée distante.
Pour ce faire, il suffit d’un peu de communication inter-process, dans sa forme la plus simple : on lance le programme C++ precédent, on lit ce qu’il écrit sur stdout, on le décode et on l’affiche.
Voici donc le code Java de la boucle principale de l’afficheur :
/**
* Main loop : launch C++ listener, get its output, draw, and loop
* @throws IOException
*/
public void run() throws IOException
ProcessBuilder pb = new ProcessBuilder("sound-source-loc") ;
pb = pb.redirectErrorStream(true) ;
Process p = pb.start() ;
InputStream is = p.getInputStream() ;
InputStreamReader isr = new InputStreamReader(is) ;
BufferedReader br = new BufferedReader(isr) ;
String line ;
while (( line = br.readLine()) != null)
int sep=line.indexOf(’ ;’) ;
float angle=Float.parseFloat(line.substring(0,sep)) ;
float relativePower=Float.parseFloat(line.substring(sep+1)) ;
//System.out.println("received sound loc : "+line) ;
_soundLocDraw.setSound(angle,relativePower) ;
Le reste est un simple affichage dans un panel graphique, et vogue la galère !
Résultats
Et bien ça marche... comme avant !
On appelle le ’robot’ pas trop fort à son extrême droite :
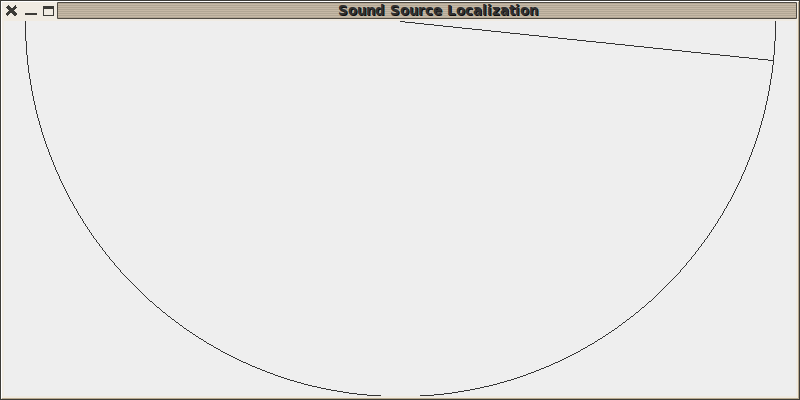
Puis un peu plus fort au milieu à gauche :
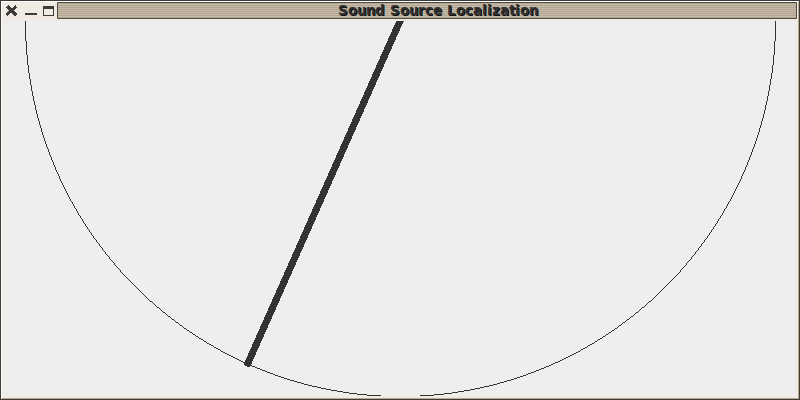
Et c’était bien là l’objectif ! La localisation marche toujours bien, avec le même affichage, mais le code est maintenant en C++, plus rapide, et sans dépendances.
Il est donc prêt a être porté sur une solution embedded, par exemple sur une Raspberry Pi avec une webcam Playstation Eye et ses multiples microphones (je dis ça au hasard, hein 🙂 )





Vos commentaires
# Le 12 décembre 2012 à 10:11, par jbot En réponse à : La localisation des sources de son : portage en C++ / ALSA
En réponse à : La localisation des sources de son : portage en C++ / ALSA
Trés interessant ! Merci pour cet article ^^
# Le 12 décembre 2012 à 12:00, par Julien H. En réponse à : La localisation des sources de son : portage en C++ / ALSA
En réponse à : La localisation des sources de son : portage en C++ / ALSA
Un usage pour la Coupe Eurobot ? Par exemple une balise qui émet un son fort et grave, et un filtre passe-bas sur les fréquences analysées ?
Répondre à ce message